
That’s an important point to understand. Not only will using the wrong method sometimes lead to pages not being removed from the index as intended, but it can also have a negative effect on SEO.
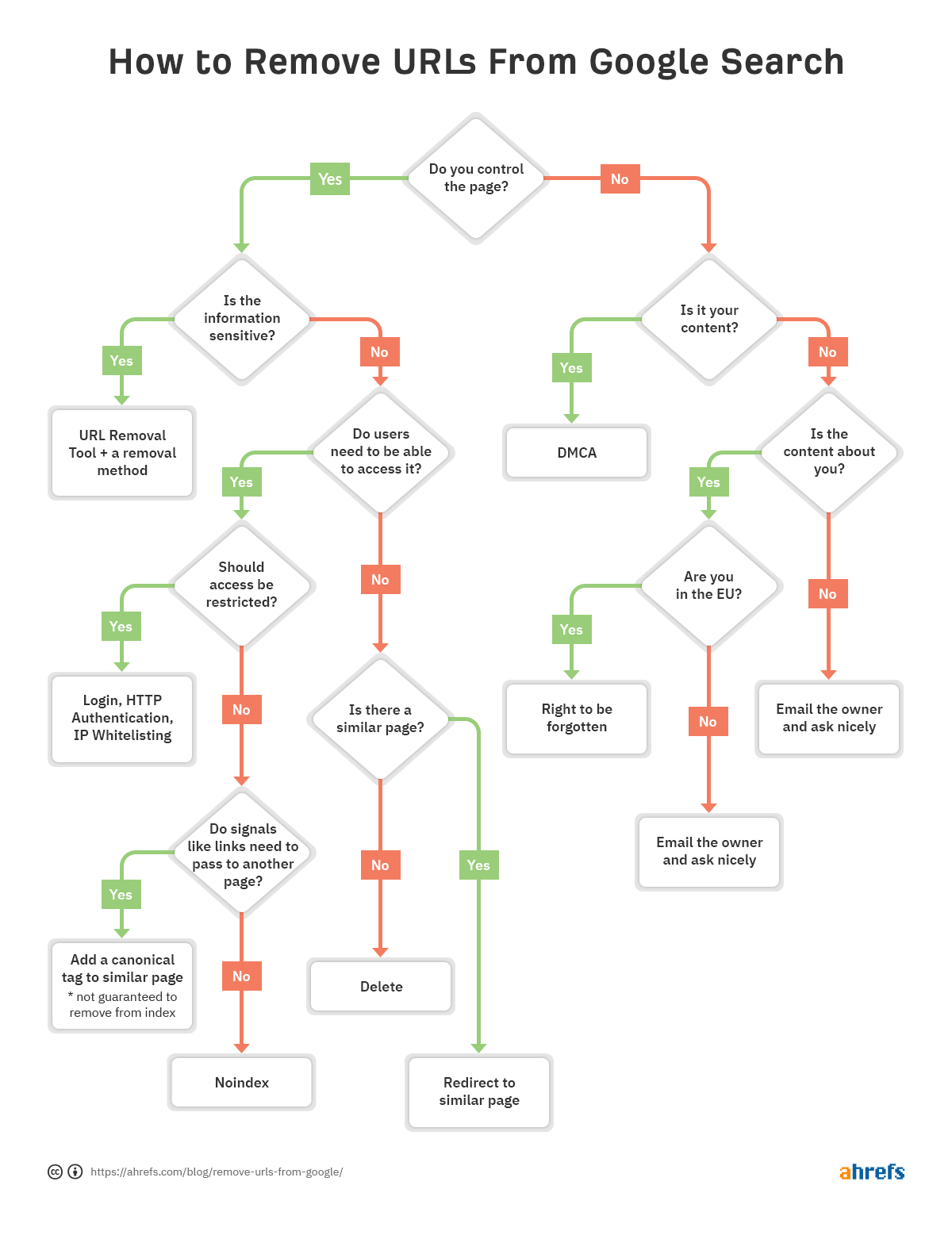
To help you quickly decide which method of removal is best for you, we made a flowchart so you can skip to the relevant section of the article.
In this post, you’ll learn:
- How to check if a URL is indexed
- Five ways to remove URLs from Google
- How to prioritize removals
- Common removal mistakes to avoid
- How to remove content that’s not on your site
- How to remove images

What I typically see SEOs do to check if content is indexed is use a site: search in Google (e.g., site:https://ahrefs.com). While site: searches can be useful for identifying the pages or sections of a website that may be problematic if they show in search results, you have to be careful because they aren’t normal queries and won’t actually tell you if a page is indexed. They may show pages that are known to Google, but that doesn’t mean they’re eligible to show in normal search results without the site: operator.
For example, site: searches can still show pages that redirect or are canonicalized to another page. When you ask for a specific site, Google may show a page from that domain with the content, title, and description from another domain. Take for example moz.com which used to be seomoz.org. Any regular user queries that lead to pages on moz.com will show moz.com in the SERPs, while site:seomoz.org will show seomoz.org in the search results as shown below.
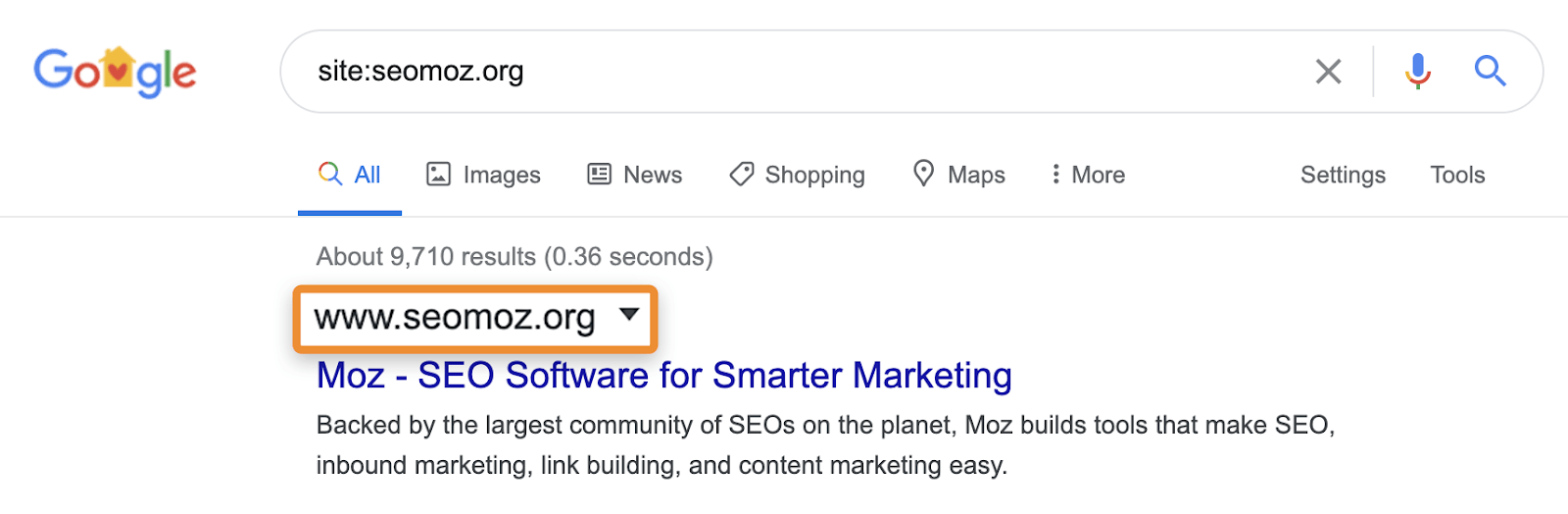
The reason this is an important distinction is that it can lead SEOs to make mistakes such as actively blocking or removing URLs from the index for the old domain, which prevents consolidation of signals like PageRank. I’ve seen many cases with domain migrations where people think they made a mistake during the migration because these pages still show for site:old-domain.com searches and end up actively harming their website while trying to “fix” the problem.
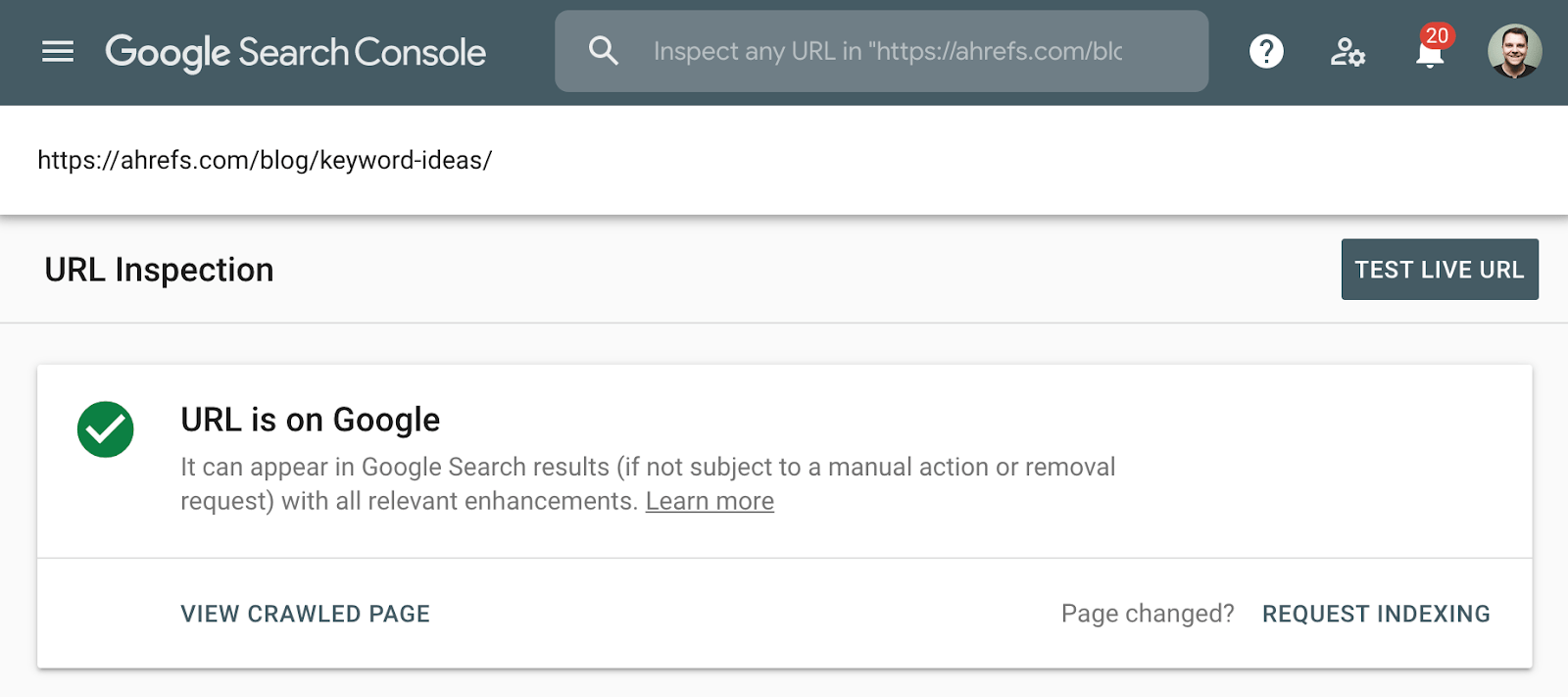
The better method to check indexation is to use the Index Coverage report in Google Search Console, or the URL Inspection Tool for an individual URL. These tools tell you if a page is indexed and provide additional information on how Google is treating the page. If you don’t have access to this, simply search Google for the full URL of your page.
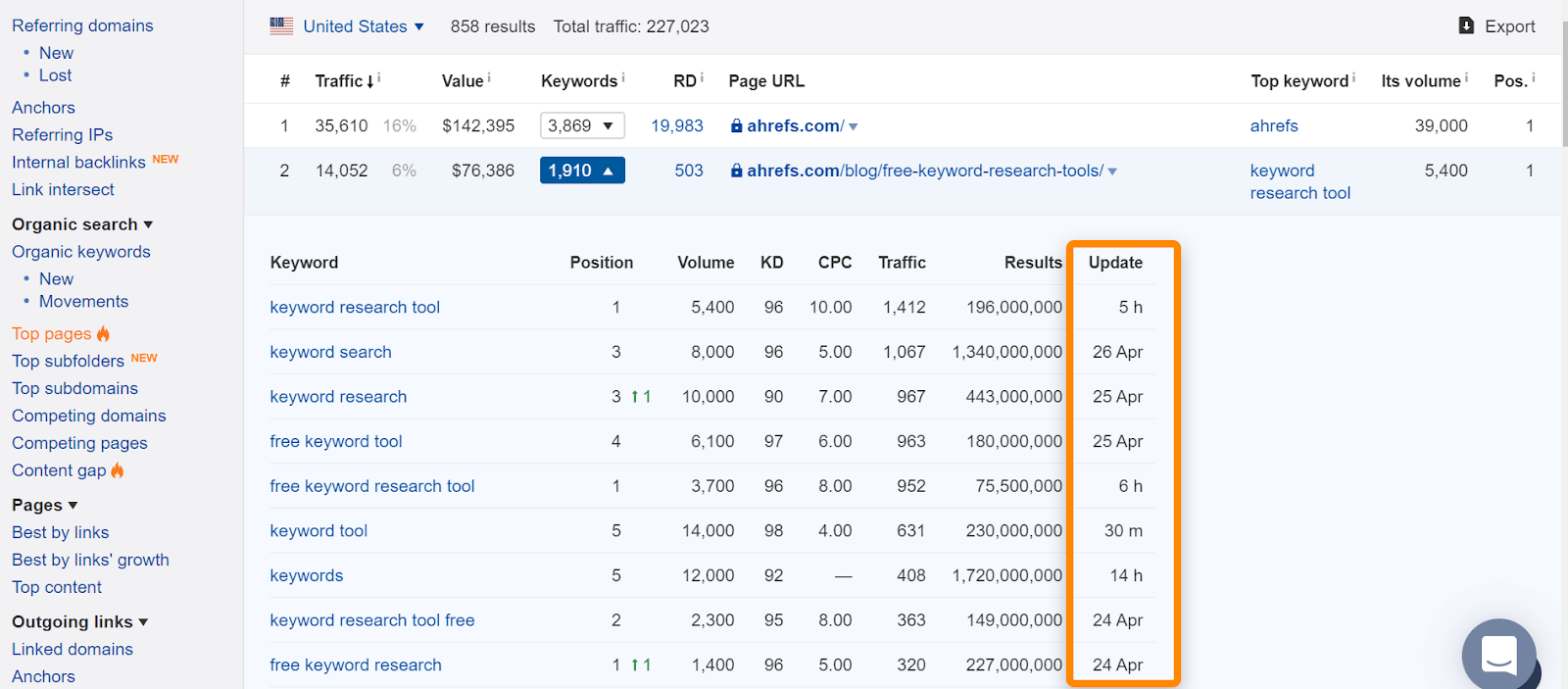
In Ahrefs, if you find the page in our “Top pages” report or ranking for organic keywords, it usually means we saw it ranking for normal search queries and is a good indication that the page was indexed. Note that the pages were indexed when we saw them, but that may have changed. Check the date we last saw the page for a query.
If there is a problem with a particular URL and it needs removing from the index, follow the flowchart at the beginning of the article to find the correct removal option, then jump to the appropriate section below.
If you remove the page and serve either a 404 (not found) or 410 (gone) status code, then the page will be removed from the index shortly after the page is re-crawled. Until it is removed, the page may still show in search results. And even if the page itself is no longer available, a cached version of the page may be temporarily available.
When you might need a different option:
- I need more immediate removal. See the URL removal tool section.
- I need to consolidate signals like links. See the canonicalization section.
- I need the page available for users. See if the noindex or restricting access sections fit your situation.
Removal option 2: Noindex
A noindex meta robots tag or x-robots header response will tell search engines to remove a page from the index. The meta robots tag works for pages where the x-robots response works for pages and additional file types like PDFs. For these tags to be seen, a search engine needs to be able to crawl the pages—so make sure they aren’t blocked in robots.txt. Also, note that removing pages from the index may prevent the consolidation of link and other signals.
Example of a meta robots noindex:
<meta name="robots" content="noindex">
Example of x-robots noindex tag in the header response:
HTTP/1.1 200 OK X-Robots-Tag: noindex
When you might need a different option:
- I don’t want users to access these pages. See the restricting access section.
- I need to consolidate signals like links. See the canonicalization section.
Removal option 3: Restricting access
If you want the page to be accessible to some users but not search engines, then what you probably want is one of these three options:
- some kind of login system;
- HTTP Authentication (where a password is required for access);
- IP Whitelisting (which only allows specific IP addresses to access the pages)
This type of setup is best for things like internal networks, member only content, or for staging, test, or development sites. It allows for a group of users to access the page, but search engines will not be able to access them and will not index the pages.
When you might need a different option:
- I need more immediate removal. See the URL removal tool section. In this particular case, you may want more immediate removal if the content you are trying to hide has been cached, and you need to prevent users from seeing that content.
Removal option 4: URL Removal Tool
The name for this tool from Google is slightly misleading as the way it works is that it will temporarily hide the content. Google will still see and crawl this content, but the pages won’t appear for users. This temporary effect lasts for six months in Google, while Bing has a similar tool that lasts for three months. These tools should be used in the most extreme cases for things like security issues, data leaks, personally identifiable information (PII), etc. For Google, use the Removals Tool and for Bing, see how to block URLs.
You still need to apply another method along with using the removal tool in order to actually have the pages removed for a longer period (noindex or delete) or prevent users from accessing the content if they still have the links (delete or restrict access). This just gives you a faster way of hiding the pages while the removal has time to process. The request can take up to a day to process.
Removal option 5: Canonicalization
When you have multiple versions of a page and want to consolidate signals like links to a single version, what you want to do is some form of canonicalization. This is mostly to prevent duplicate content while consolidating multiple versions of a page to a single indexed URL.
You have several canonicalization options:
- Canonical tag. This specifies another URL as the canonical version or the version you want to be shown. If pages are duplicate or very similar, this should be fine. When pages are too different, the canonical may be ignored as it is a hint and not a directive.
- Redirects. A redirect takes a user and a search bot from one page to another. 301 is the most commonly used redirect by SEOs, and it tells the search engines that you want the final URL to be the one shown in search results and where signals are consolidated. A 302 or temporary redirect tells search engines you want the original URL to be the one to remain in the index and to consolidate signals there.
- URL parameter handling (deprecated in early 2022 and no longer useful). A parameter is appended to the end of the URL and typically includes a question mark, like ahrefs.com?this=parameter. This tool from Google used to let you tell them how to treat URLs with specific parameters. For instance, you used to be able to specify if the parameter changed the page content or if it was just used to track usage.
If you have multiple pages to remove from Google’s index, then they should be prioritized accordingly.
Highest priority: These pages are usually security-related or related to confidential data. This includes content that contains personal data (PII), customer data, or proprietary information.
Medium priority: This usually involves content meant for a specific group of users. Company intranets or employee portals, content meant for members only, and staging, test, or development environments.
Low priority: These pages usually involve duplicate content of some kind. Some examples of this would include pages served from multiple URLs, URLs with parameters, and again could include staging, test, or development environments.
I want to cover a few of the ways I usually see removals done incorrectly and what happens in each scenario to help people understand why they don’t work.
Noindex in robots.txt
While Google used to unofficially support noindex in robots.txt, it was never an official standard and they’ve now formally removed support. Many of the sites that were doing this were doing so incorrectly and harming themselves.
Blocking from crawling in robots.txt
Crawling is not the same thing as indexing. Even if Google is blocked from crawling pages, if there are any internal or external links to a page they can still index it. Google won’t know what is on the page because they will not crawl it, but they know a page exists and will even write a title to show in search results based on signals like the anchor text of links to the page.
Nofollow
This commonly gets confused for noindex, and some people will use it at a page level expecting the page not to be indexed. Nofollow is a hint, and while it originally stopped links on the page and individual links with the nofollow attribute from being crawled, that is no longer the case. Google can now crawl these links if they want to. Nofollow was also used on individual links to try to stop Google from crawling through to specific pages and for PageRank sculpting. Again, this no longer works since nofollow is a hint. In the past, if the page had another link to it, then Google could still discover from this alternate crawl path.
Note that you can find nofollowed pages in bulk using this filter in the Page Explorer in Ahrefs’ Site Audit.
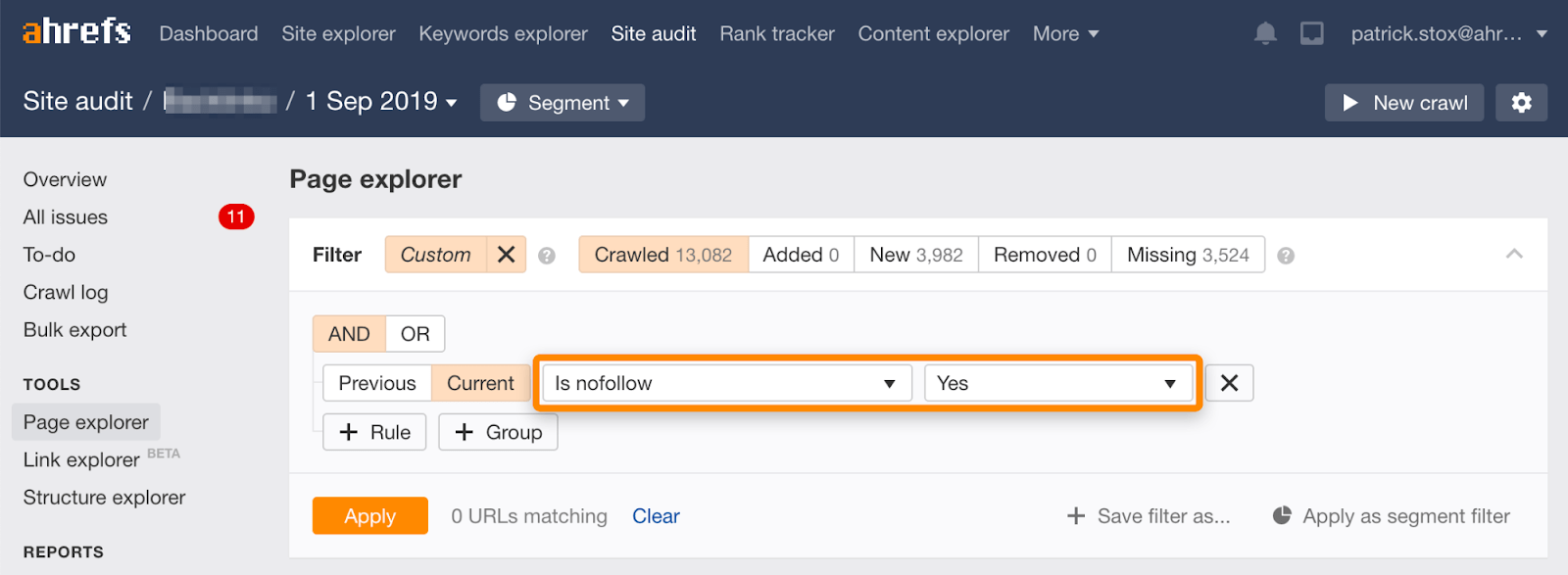
As it rarely makes sense to nofollow all links on a page, the number of results should be zero or close to zero. If there are matching results, I urge you to check whether the nofollow directive was accidentally added in place of noindex and to choose a more appropriate method of removal if need be.
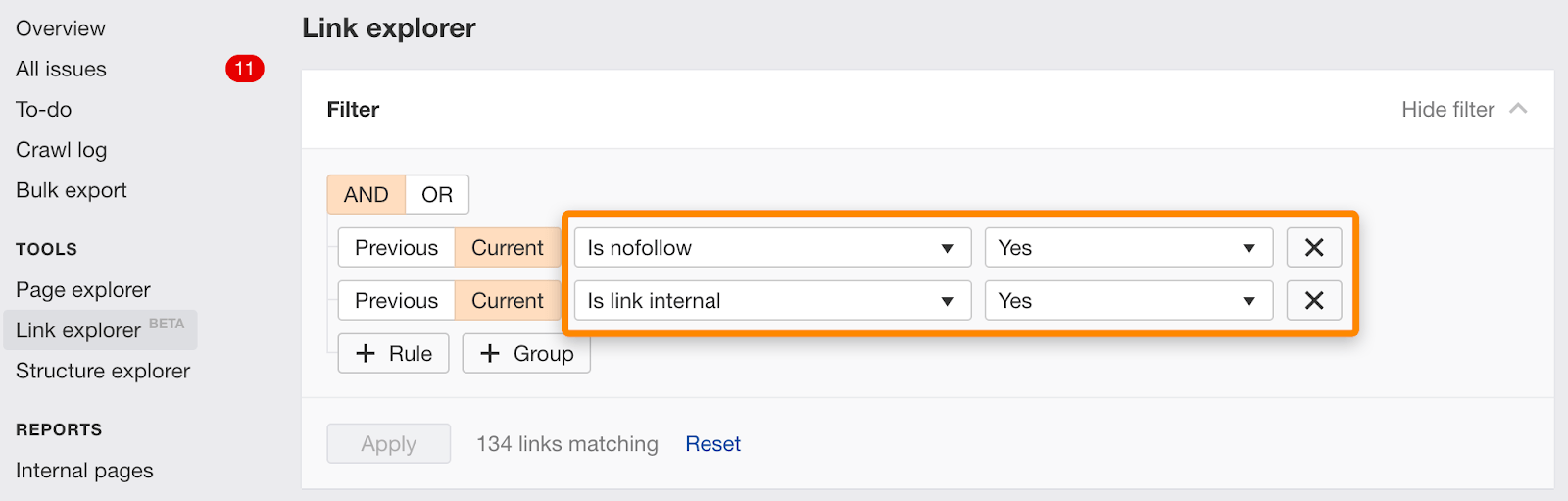
You can also find individual links marked nofollow using this filter in Link Explorer.
Noindex and canonical to another URL
These signals are conflicting. Noindex says to remove the page from the index, and canonical says that another page is the version that should be indexed. This may actually work for consolidation as Google will typically choose to ignore the noindex and instead use the canonical as the main signal. However, this isn’t an absolute behavior. There’s an algorithm involved and there’s a risk that the noindex tag could be the signal counted. If that’s the case, then pages won’t consolidate properly.
Note that you can find noindexed pages with non-self-referential canonicals using this set of filters in the Page Explorer in Site Audit:
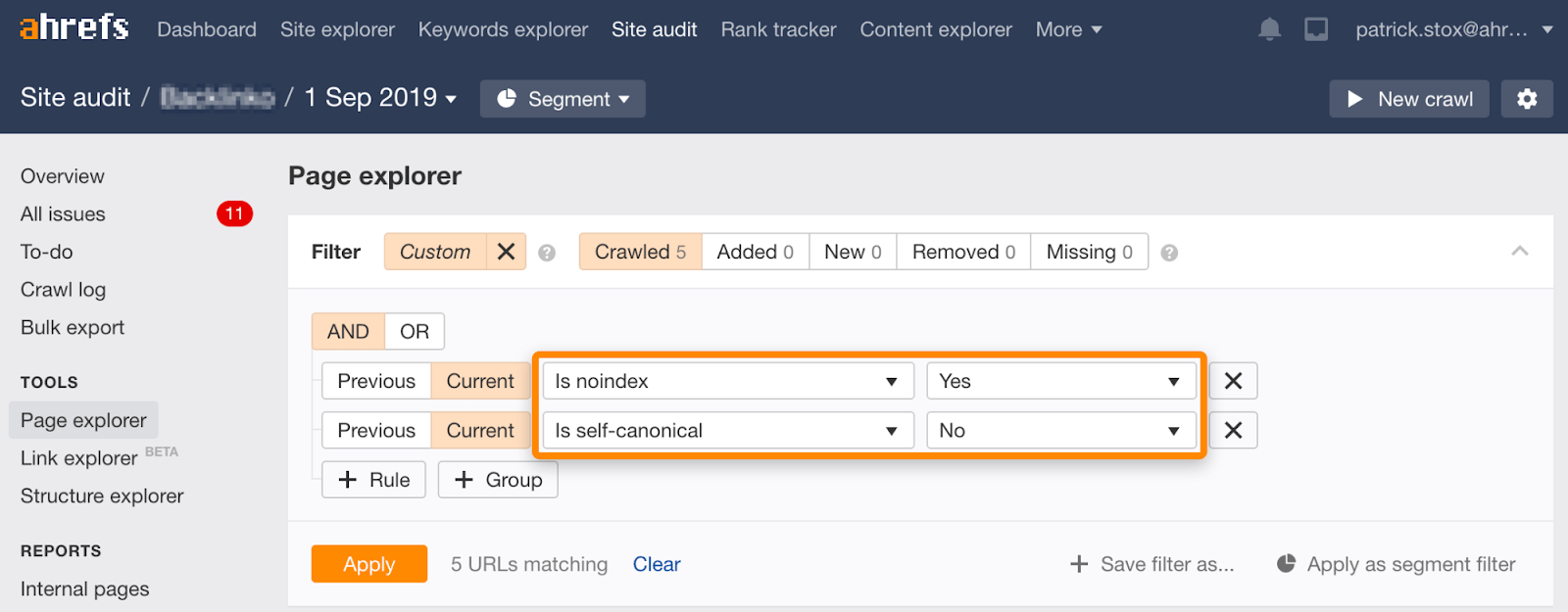
Noindex, wait for Google to crawl, then block from crawling
There are a couple of ways this usually happens:
- Pages are already blocked but are indexed, people add noindex and unblock so that Google can crawl and see the noindex, then block the pages from crawling again.
- People add noindex tags for the pages they want removed and after Google has crawled and processed the noindex tag, they block the pages from crawling.
Either way, the final state is blocked from crawling. If you remember, earlier, we talked about how crawling is not the same as indexing. Even though these pages are blocked, they can still end up in the index.
If you own the content that’s being used on another website, you may be able to file a claim based on the Digital Millennium Copyright Act (DMCA). You can use Google’s Copyright Removal tool to do what’s called a DMCA takedown, which requests the removal of any copyrighted material.
What if it’s content about you but not on a site you own?
If you’re in the EU, you can have content removed that contains information about you thanks to a court order for the right to be forgotten. You can request to have personal information removed using the EU Privacy Removal form.
To remove images from Google, the easiest way is with robots.txt. While the unofficial support for removing pages was removed from robots.txt as we mentioned earlier, simply disallowing the crawl of images is the right way to remove images.
For a single image:
User-agent: Googlebot-Image Disallow: /images/dogs.jpg
For all images:
User-agent: Googlebot-Image Disallow: /
Final thoughts
How you remove URLs is fairly situational. We’ve talked about several options, but if you’re still confused which is right for you, refer back to the flowchart at the start.
You can also go through the legal troubleshooter provided by Google for content removal.
Have questions? Let me know on Twitter.



